Introduction
Before getting started to examine Access Management and
Request Fulfilment it is better to understand the concept of ITSM. In this
introduction we will try to describe it and name its processes. Knowing what it
stands for is going to help us to undertand other detailed explanations. Service
Management is a customer-focused approach to delivering information
technology. Service Management provides a framework to structure IT-related
activities and the interactions of IT technical personnel with customers and
clients. Services allow customers to do business without worrying about
underlying technology or IT infrastructure. Services must evolve in order to
continue to meet the needs of the customer and respond to technological changes
and advances. The Service Lifecycle is the overall framework used to identify,
define, manage, and retire IT services.
IT Service
Management (ITSM) is defined as a process-based practice intended to align the
delivery of information technology (IT) services with needs of the business,
which emphasizes benefits to customers. While the process at its core concerns
technology, this focus on the client is key.
The purpose of Service Operations can be summed as:
• To coordinate and
deliver key activities and processes required to provide and manage
services at agreed levels to the business, users and customers
• To manage the technology and toolsets that are used to deliver and support services
• To manage, measure, control and feedback improvements in the day to day operations
• To monitor performance, assess metrics and gather data to input into the Continual Service Improvement Process Area
services at agreed levels to the business, users and customers
• To manage the technology and toolsets that are used to deliver and support services
• To manage, measure, control and feedback improvements in the day to day operations
• To monitor performance, assess metrics and gather data to input into the Continual Service Improvement Process Area
ITSM is often implemented through a
set of frameworks. There are many, some of which are complimentary to others,
such as ITIL, COBIT, PMBOK, PRINCE, CMMI. IT Services
has selected to build its path on ITIL.
After all these general knowledge
about ITSM we can say that it is mainly about handling user
requests, fixing services carrying operation problem tasks.This view handles a
service after is has been deployed and is active to the customer.
This volume has following processes:
·
Request
Fulfilment
·
Access
Management
·
IT
Facilities Management
These processes have a organized relation
between them. Figure below shows how they intract eachother.

On the other hand we need to have knowledge about some
expressions, some important main terms and guidelines of Service Operations:
·
Internal view (x) external view: internal IT view is the way components are
managed to deliver a service. External business view is the way a client sees a
service. There is an eternal conflict between this two views in a company and
there is a need to try to achieve a balance between them.
·
Stability (x) responsiveness: no matter how a good service is provided, there
will be always a need to change something. Considering that every change is a
potential risk in service stability, a change would not be good. But business
needs changes, and they are going to happen anyway. Balance here is to change
services without losing stability.
·
These changes may be at several levels, as technology, capacity
management, grow strategy, problems experienced.
·
Quality of service (x) cost of service: this
is about having continous Quality
Improvements and consequences of all these effort to cost to deliver the
service.
·
Reactive (x) proactive: management that is solely reactive is not
effective, but management that is overly proactive is not effective either.
When staff are too proactive, this may result in increased expense and
distracted staff.
·
Event or Alert: a change in state that
has significance for management.
·
Incident: an unplanned interruption in service or loss of quality.
·
Failure: a loss of ability to operate service. Normally a failure results in an
incident.
·
Error:
a design malfunction that causes a failure.
·
Problem: A cause of one or more Incidents. The cause is not usually known at
the time a Problem Record is created
·
Known error: a problem that has documented root cause or a workaround.
We will be working on the two important parts of these
processes of Service Management: Access Management and Request Fullfillment.
You will be directed to other pages for further information by clicking the
blog links next to them.
1) Access Management
People in IT Departments faces
difficult challenges every single day. For all the people work in IT
departments providing an excellent service is not an easy task. The information
in your company must flow easily throughout the organizations in a quick and
secure way. So in all these considerations, you must ensure its availability
and have the necessary resources to access it.
The
question is: how can your IT department know what information must be available
to each user? And how can you control that every user has access only to the information
that is strictly necessary? The answer is having a well organized Access
Management organization.
People
can come to you with questions like “I haven’t been using this application for
a long time so I just forgot my password. What am I supposed to do?” or “I have
a new position in this company so I need to be able to Access new specific
parts of the system. How can I get this permissions?” etc. All these questions
can be answered easily and quickly if you have a well organized management system
of accessing in the company.

The image above presents an example of accessing several different points
by different users with a not well- organized Access management system. To make things even
worse, if there is no IT Service
Catalogue defined, it’s almost
impossible to maintain any form of Access Management.

Well-organized
Access Management relies on other parts of Service Management to do their part
as well, e.g. Change Management, Service Desk, and Information Security
Process
activities of Access Management
The role of Access Management is to enable
users (and groups of users) with appropriate levels of access to the services
presented in the IT Service Catalogue. Access is the term that describes the level
and extent of the service functionality available to the user, and is related
to the user identity,
which uniquely distinguishes one individual from another, verifying /
confirming their status within the organization. User rights (or privileges) refer to actual
settings within a service that are granted to the user or user group, e.g.
read, write, list, execute, delete, change, etc. With all necessary basics
covered, lets look at process activities of the Access Management.
Policies and principles of Access Management with basic concepts
Access Management is the process that enables
users to use the services that are documented in the Service Catalogue. It
comprises the following basic concepts:
• Access refers to
the level and extent of a service’s functionality or data that a user is
entitled to use.
• Identity refers to the information
about them that distinguishes them as an individual and which verifies their
status within the organization. By definition, the Identity of a user is unique
to that user.
• Rights (also
called privileges) refer to the actual settings whereby a user is provided
access to a service or group of services. Typical rights, or levels of access,
include read, write, execute, change, delete.
• Services or service groups. Most
users do not use only one service, and users performing a similar set of activities
will use a similar set of services. Instead of providing access to each service
for each user separately, it is more efficient to be able to grant each user –
or group of users – Access to the whole set of services that they are entitled
to use at the same time.
• Directory
Services refers to a specific type of tool that is used to manage
access and rights.
Process activities, methods and techniques
1.1) Requesting Access
This is an excellent place to start defining your Access Management
procedures, as requests to change an access level generally emanate from only a
few, well-defined areas. For instance, the Human Resources system could
generate a standard request for access whenever someone is hired, promoted or
transferred or leaves the company. Other entry points for a request for access
could be a Request for Change (RFC) into the Change Management System (Service
Transition) or a Service Request from the Request Fulfilment System (Service
Operation). You can include the procedure for requesting access as
part of the Service Catalog (Service
Design).
In general, the Security policies will define which areas and
departments may request access, and the Access Management process will design
the mechanisms to carry out that request. So, if need to sum all the
features of requesting Access we can list them like this. Access (or
restriction) can be requested using one of any number of mechanisms, including:
• A standard request generated by
the Human Resource system. This is generally done whenever a person is hired,
promoted, transferred or when they leave the company
• A Service
Request submitted via the Request Fulfilment system
• By
executing a pre-authorized script or option (e.g. downloading an application
from a staging server as and when it is needed).
1.2) Verification
The verification activity verifies a request for access to ensure that
the user requesting the access is who he/she says he/she is, and that the user
has a legitimate requirement for the service. There are many methods for
verifying the user’s identity, ranging from low-tech personal recognition to
high-tech biometric data. Establishing the legitimacy of the request requires a
few more verification steps. For instance, you may require the Human Resources
department or the appropriate manager to co-sign requests to add new users. The
Change
Management process should include a review of Access Management rights
as it evaluates RFCs to specify who should have access to the service and
whether existing users are still valid. Depending on the levels of risk to the
organization, the Security policies may define different levels of
verifications to access different services. For example, a request to access
the banking system may carry a much higher level of verification than a request
to add a new employee to the internal network. Access Management needs to
verify every request for access to an IT service from two
perspectives:
• That the
user requesting access is who they say they are
• That they
have a legitimate requirement for that service.
The first category is usually achieved by
the user providing their username and password. Depending on the organization’s
security policies, the use of the username and password are usually accepted as
proof that the person is a legitimate user. However, for more sensitive services
further identification may be required (biometric, use of an electronic access
key or encryption device, etc.). The second category will require some
independent verification, other than the user’s request. For example:
• Notification
from Human Resources that the person is a new employee and requires both a
username and access to a standard set of services
• Notification
from Human Resources that the user has been promoted and requires access to
additional resources
• Authorization
from an appropriate (defined in the process) manager
• Submission
of an RFC (with supporting evidence) through Change Management, or execution of
a pre-defined Standard
Change
• A policy
stating that the user may have access to an optional service if they need it.
For new services the Change Record should specify which users or groups of users will have access to the Service. Access Management will then check to see that all the users are still valid and automatically provide access as specified in the RFC.

Contractor employees requiring Access
to the Portal. In this example, the contractor user initiates a request for
Access to the Enterprise Portal.
1.3) Providing Rights
Once it has verified a user, Access Management provides the appropriate
rights to him/her. However, Access Management should also be on the lookout for
any role
conflicts
that might occur. For example, two separate
accesses might be granted by different requesters to a single contract worker –
one authorizing him to log time sheets for a project and the other authorizing
him to approve all payment on work for the same project. In addition, large organizations
may have many roles and groups, and sometimes a user may end up with mutually
exclusive roles. Access Management does not fix role conflicts or duplications
itself, but it informs the originators of the access requests about the issues.
Again, the Security policy defines the rights that should be available to an
individual, and Access Management grants rights based on this information. The
Security team and the Access Management team must work together to build awareness
within Access Management regarding potential role conflicts and mutual
exclusions.

The more roles and groups that exist, the
more likely that Role Conflict will
arise. Role Conflict in this context refers to a situation where two specific
roles or groups, if assigned to a single user, will create issues with
separation of duties or conflict of interest. Role Conflict can be avoided by
careful creation of roles and groups, but more often they are
caused by policies and decisions
made outside of Service Operation – either by the business or by
different project teams working during Service
Design. In each case the conflict must be documented and escalated to the
stakeholders to resolve. Whenever roles and groups are defined, it is possible
that they could be defined too broadly or too narrowly. There will always be
users who need something slightly different from the pre-defined roles. In these
cases, it is possible to use standard roles and then add or subtract specific
rights as required – similar to the concept of Baselines and Variants in Configuration
Management (see Service
Transition publication). However, the decision to
do this is not in the hands of individual operational staff members. Each exception
should be coordinated by Access Management and approved through the originating
process. Access Management should perform a regular review of the roles and
groups that it has created and manage to ensure that they are appropriate for
the services that IT delivers and supports – and obsolete or unwanted
roles/groups should be removed.
1.4) Monitoring Identity Status
One of the problems with many manual Access Management systems in use
today is that there is no easy way to monitor when a user changes roles or
Identity Status. Typical events that trigger a change in Identity Status are
job changes, promotions or demotions, transfers, resignation or death,
retirement, disciplinary action, dismissals. By identifying trigger events
similar to the above, it is possible to seek Access Management tools that will
automate the Access Management process and provide an audit trail. Security
policies define such trigger events, and Access Management builds ways to
capture them.
As users work in the organization, their roles change
and so also do their needs to access services. Examples of changes include:
• Job changes. In this
case the user will possibly need access to different or additional services.
• Promotions or demotions. The user
will probably use the same set of services, but will need access to different
levels of functionality or data.
• Transfers. In this
situation, the user may need access to exactly the same set of services, but in
a different region with different working practices and different sets of data.
• Resignation
or death. Access needs to be completely
removed to prevent the username being used as a security loophole
• Retirement. In many
organizations, an employee who retires may still have access to a limited set
of services, including benefits systems or systems that allow them to purchase
company products at a reduced rate.
• Disciplinary action. In some
cases the organization will require a temporary restriction to prevent the user
from accessing some or all of the services that they would normally have access
to. There should be a feature in the process and tools to do this, rather than
having to delete and reinstate the user’s access rights.
• Dismissals. Where an
employee or contractor is dismissed, or where legal action is taken against a
customer (for example for defaulting on payment for products purchased on the
Internet), access should be revoked immediately. In addition, Access
Management, working together with Information Security Management, should take
active measures to prevent and detect malicious action against the organization
from that user.

Access Management should understand and document the typical User Lifecycle for each type of
user and use it to automate the process. Access Management tools should provide
features that enable a user to be moved from one state to another, or from one
group to another, easily and with an audit trail.
1.5) Logging and Tracking Access
All Technical
and Application
Management
monitoring activities should include reviews of Access rights and utilization
to ensure that the rights are being properly used. The review should direct all
exceptions to Incident
Management
for investigation. Of course, it may be
know as it could reveal vulnerabilities in the
organization’s security tools or policies.
Furthermore, Access Management may provide access records to
assist corporate investigations into user activity. The Security group develops
the requirements for monitoring and tracking, and Access Management develops
the pursuant capabilities.
Access Management should not only respond to requests. It is also
responsible for ensuring that the rights that they have provided are being
properly used. In this respect, Access Monitoring and Control must be included
in the monitoring activities of all Technical and Application Management
functions and all Service Operation processes. Exceptions
should be handled by Incident Management, possibly using Incident Models
specifically designed to deal with abuse of access rights. It should be noted
that the visibility of such actions should be restricted. Making this information
available to all who have access to the Incident Management system will expose
vulnerabilities.
Information
Security Management plays a vital role in detecting unauthorized access
and comparing it with the rights that were provided by Access Management. This
will require Access Management involvement in defining the parameters for use
in Intrusion Detection tools. Access Management may also be required to provide
a record of access for specific Services during forensic investigations. If a
user is suspected of breaches of policy, inappropriate use of resources, or
fraudulent use of data, Access Management may be required to provide evidence
of dates, times and even content of that user’s access to specific Services.
This is normally provided by the Operational staff of that service, but working
as part of the Access Management process.
1.6) Removing or Restricting Rights
Users do not stay in the same jobs or roles forever, and neither should
their access rights. This is another place to set up standard procedures and
policies to more easily identify events requiring the removal or restriction of
rights. Some examples are death, resignation, dismissal, changed user roles,
and physical moves to areas with different access rights. Based
on such changes in User status or
access requirements, Access Management adjusts Access rights according to Security
policy.

Just as Access Management provides rights to
use a Service, it is also responsible for revoking those rights. Again, this is
not a decision that it makes on its own. Rather, it will execute the decisions
and policies made during Service Strategy
and Design and also decisions made by managers in the organization. Removing
access is usually done in the following circumstances:
• Death
• Resignation
• Dismissal
• When the
user has changed roles and no longer requires access to the service
• Transfer
or travel to an area where different regional access applies.
You
can see the Access Management process flow in detail by clicking the
link (It was not put in this document because
it is a quite large image to see details here)
{kind=link}
2) Request Fulfilment
To understand this field we
need to describe what is a service request before getting started. Then we will
know what we need to do and actually what we fulfill when we receive a request.
After all we need to explain what is an “incident” and “request”. Incidents and Requests are often lumped together in the
Service Desk as “calls” or “tickets”. And to some degree, they are both very
similar – but Requests tend to get lost among the urgency of Incidents, and the
result is unhappy customers. How are the two different?
Incident – an unplanned interruption to a service. (something was or should be working but is not.)
Request – customer requires a service they currently do not have. Request are often for small changes that are done frequently and have low risk. Things like access to a resource, applications or server – new or replacement computer hardware, mobility, and remote access tokens.
The term service request is used as a
generic description for many, varying types of request from users that are made
to the IT department. Many of these service requests are actually small changes
– low risk, frequently occurring, low cost, etc. Examples of service requests
include a request to install an additional software application onto a
particular workstation, a request to relocate some items of desktop equipment
or maybe just a question requiring information. Their size, frequency and low
risk nature means that they are more appropriately handled by a separate
process, rather than being allowed to congest the normal incident and change
management processes. This process is request fulfilment. The
purpose and scope of request fulfilment: Request fulfilment is the process
of dealing with service requests from the users. The objectives of the request
fulfilment process include: To provide a channel for users to request and
receive standard services for which a pre-defined approval and qualification
process exists. To provide information to users and customers about the
availability of services and the procedure for obtaining them. To source and
deliver the components of requested standard services (e.g. licences and
software media).
Process Activities, Methods and Techniques of Request Fulfilment
2.1)MenuSelection
Service requests can be requested by users via the Service Desk; however, request fulfilment offers the opportunity to use self help practices where users can generate a service request themselves using technology that links into service management tools. Users should be offered a menu type selection via a web interface, so that they can select and input details of service requests from a pre-defined list.
Specialist web tools to offer this type of ‘shopping basket’ experience can be used together with interfaces directly to the back-end integrated ITSM tools, or other more general business process automation or Enterprise Resource Planning (ERP) tools that may be used for management of the Request Fulfilment activities.
2.1)MenuSelection
Service requests can be requested by users via the Service Desk; however, request fulfilment offers the opportunity to use self help practices where users can generate a service request themselves using technology that links into service management tools. Users should be offered a menu type selection via a web interface, so that they can select and input details of service requests from a pre-defined list.
Specialist web tools to offer this type of ‘shopping basket’ experience can be used together with interfaces directly to the back-end integrated ITSM tools, or other more general business process automation or Enterprise Resource Planning (ERP) tools that may be used for management of the Request Fulfilment activities.

2.2) Financial Approval
One
important extra step that is likely to be needed when dealing with a service
request is that of financial approval. Most
requests will have some form of financial implications, regardless of the type
of commercial arrangements in place. The cost of
fulfilling the request must first be established.
It may be possible to agree fixed prices for ‘standard’ requests – and prior
approval for such requests may be given as part of the organization’s overall
annual financial management. In all other cases, an estimate of the cost must be
produced and submitted to the user for financial approval (the user may need to
seek approval up their management/financial chain). If approval is given, in
addition to fulfilling the request, the process must also include charging (billing
or cross-charging) for the work done – if charging is in place. Some service requests may need an
additional step to add financial approval.
2.3) Other Approval
Some service requests may need further
approval such as compliance related or wider business approval. Request
fulfilment must have the ability to define and check such approvals where
needed.
2.4) Fullfillment
The
actual fulfilment activity/activities will depend upon the nature of the service
request. Some simpler requests may be completed by the Service Desk, acting as first line support, while others
will have to be forwarded to specialist groups and/or suppliers for fulfilment.
Some organizations may have specialist fulfilment groups (to ‘pick, pack and dispatch’) – or may have outsourced some fulfilment activities to a third-party supplier(s). The Service Desk should monitor and chase progress and keep users informed throughout, regardless of the actual fulfilment source.
Some organizations may have specialist fulfilment groups (to ‘pick, pack and dispatch’) – or may have outsourced some fulfilment activities to a third-party supplier(s). The Service Desk should monitor and chase progress and keep users informed throughout, regardless of the actual fulfilment source.
2.5)
Closure
When the service request has been fulfilled it must be referred back to
the Service Desk for closure. The Service Desk should check that the user is
satisfied with the outcome before closure takes place
Most
requests will be triggered through either a user calling the Service Desk or a
user completing some form of self-help web-based input screen to make their request.
The latter will often involve a selection from a portfolio of available request
types. The primary interfaces with Request Fulfilment include:
• Service Desk/Incident Management: Many Service Requests may come in via the Service
Desk and may be initially handled through the Incident Management process.
Some organizations may choose that all requests are handled via this route –
but others may choose to have a separate process, for reasons already discussed
earlier in this chapter.
You can see the Request Fulfilment
process flow in detail by clicking the
link (It was not put in this document because
it is a quite large image to see details here)
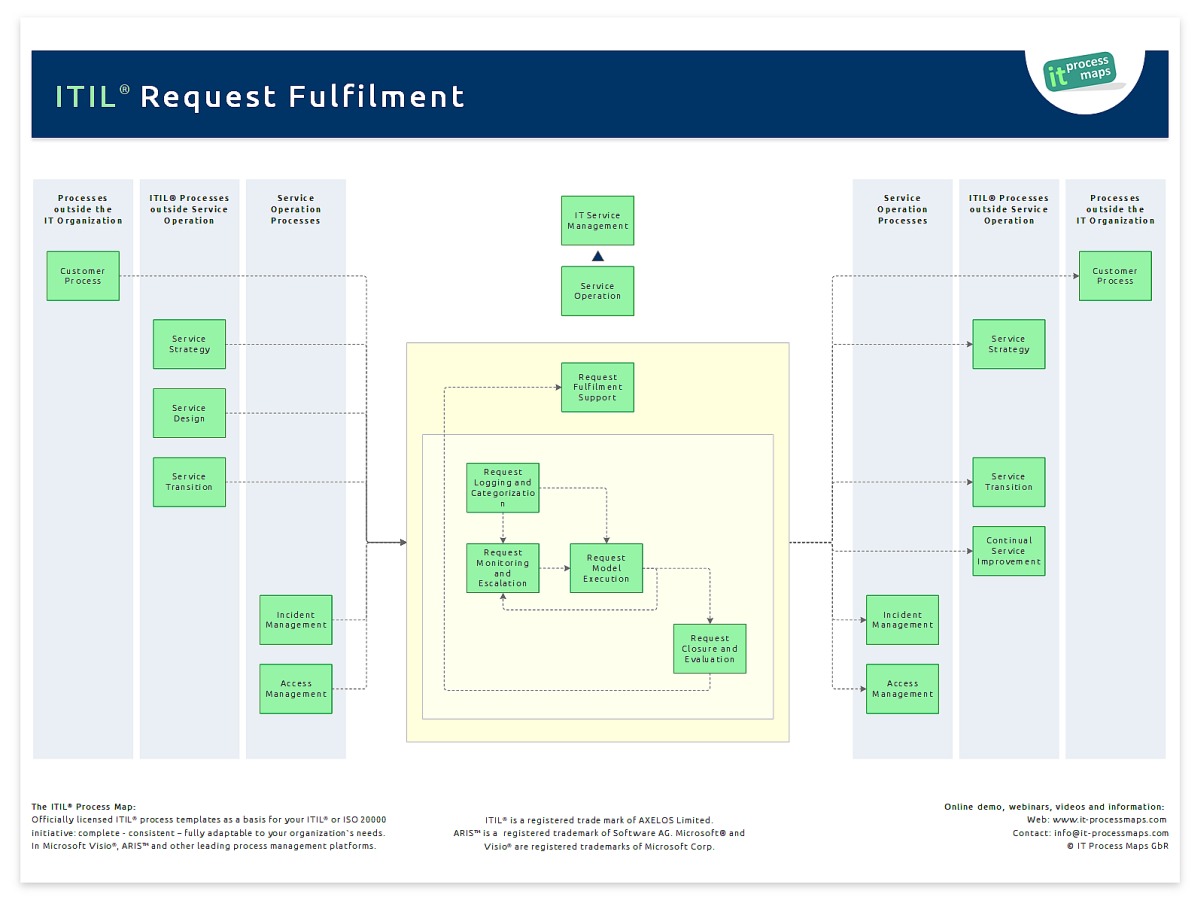{kind=link}
Events are typically notifications created by an IT service, Configuration Item (CI) or monitoring tool.
Effective Service Operation is dependent on knowing the status of the
infrastructure and detecting any deviation from normal or expected operation. This
is provided by good monitoring and control
systems, which are based on two types of
tools:
• Active
monitoring tools that poll key CIs to determine
their status and availability. Any exceptions will generate an alert that needs to
be communicated to the appropriate tool or team for action
• Passive
monitoring tools that detect and correlate operational alerts
or communications generated by CIs.
Purpose/goal/objective
The ability to detect events, make sense of them and
determine the appropriate control action is provided by Event Management. Event Management is therefore the basis for Operational Monitoring and
Control. In addition, if these events are programmed to communicate operational
information as well as warnings and exceptions, they can be used as a basis for
automating many routine Operations Management activities, for example executing scripts on remote
devices, or submitting jobs for processing, or even dynamically balancing the
demand for a service across multiple devices to enhance performance.
Event Management therefore provides the entry point
for the execution of many Service Operation processes and activities.
Scope
Event Management can be applied to any aspect of Service Management that needs to be controlled and which can be automated. These include:
• Configuration Items:
• Some CIs will be included because their status needs to change
frequently and Event Management can be used to automate this and update the CMS
(e.g. the updating of a file server).
• Security (e.g. intrusion detection)
• Normal activity (e.g. tracking the use of an application or the
performance
of a server).
These two areas are very closely related, but slightly different in
nature. Event Management is focused on generating and detecting meaningful
notifications about the status of the IT
Infrastructure and services.
While it is true that monitoring is required to detect and track these
notifications, monitoring is broader than Event Management.
Value to Business
Event Management’s value to the business is generally
indirect; however, it is possible to determine the basis for its value as
follows:
• Event Management provides mechanisms for early detection of incidents.
In many cases it is possible for the incident to be detected and
assigned to the appropriate group for action before any actual service outage occurs.
• Event Management makes it possible for some types of
automated activity to be monitored by exception – thus removing the need for expensive and resource intensive
real-time monitoring, while reducing downtime.
Policies/principles/basic concepts
There are many different types of events, for example:
• Events that signify regular operation:
• notification that a scheduled workload has
completed
• Events that signify an exception
• a PC scan reveals the installation of unauthorized
software.
Process
activities, methods and techniques

This figure is a high-level and generic representation
of Event Management. It should be
used as a reference and definition point, rather than an actual Event
Management flowchart. Each activity in this process is described below.
Event occurs
Events occur continuously, but not all of
them are detected or registered. It is therefore important that everybody
involved in designing, developing, managing and supporting IT services and
the IT Infrastructure that they run on understands what types of event need
to be detected.
Event notification
Most CIs are designed to communicate certain information about
themselves in one of two ways:
• A device is interrogated by a management tool, which
collects certain targeted data. This is often referred to as polling.
Many CIs are configured to generate a standard set of
events, based on the designer’s experience of what is required to operate the CI, with
the ability to generate additional types of event by ‘turning on’ the relevant
event generation mechanism. For other CI types, some form of ‘agent’ software
will have to be installed in order to initiate the monitoring. Often this monitoring feature is
free, but sometimes there is a cost to the licensing of the tool.
In an ideal world, the Service
Design process should define which events need to be generated and then specify how
this can be done for each type of CI. During Service Transition, the event
generation options would be set and tested.
Event detection
Once an Event notification has been generated, it will be detected by an
agent running on the same system, or transmitted directly to a management tool
specifically designed to read and interpret the meaning of the event.
Event filtering
The purpose of filtering is to decide whether to
communicate the event to a management tool or to ignore it. If ignored, the event will usually be
recorded in a log file on the device, but no further action will be taken.
The reason for filtering is that it is not always possible to turn Event notification
off, even though a decision has been made that it is not necessary to generate
that type of event. It may also be decided that only the first in a series of repeated Event notifications
will be transmitted.
Significance of events
Every organization will have its own categorization of the significance
of an event, but it is suggested that at least these three broad categories be
represented:
• Informational: This refers to an event that does not
require any action and does not represent an exception. They are typically
stored in the system or service log files and kept for a predetermined period.
Informational events are typically used to check on the status of a
device or service, or to confirm the successful completion of an activity.
Informational events can also be used to generate statistics (such as the
number of users logged on to an application during a certain period) and as input into
investigations (such as which jobs completed successfully before the transaction processing
queue hung). Examples of informational events include:
• A user logs onto an application
• A job in the batch queue completes successfully
• A device has come online
• A transaction is completed successfully.
• Warning: A warning is an event that is
generated when a service or device is approaching a threshold. Warnings are intended to notify
the appropriate person, process or tool so that the situation can be checked and the
appropriate action taken to prevent an exception. Warnings are not typically raised for a
device failure.
Although there is some debate about whether the
failure of a redundant evidence is a warning or an exception (since the service
is still available). A good rule is that every failure should be treated as an
exception, since the risk of an incident impacting the business is much greater. Examples of
warnings are:
• Memory utilization on a server is currently at 65%
and increasing. If
it reaches 75%, response times will be unacceptably long and the
OLA for that department will be breached.
• The collision rate on a network has increased by 15%
over the past The collision rate on a network has increased by 15% over the
past hour.
• Exception: An exception means that a service or device is
currently operating abnormally (however that has been defined). Typically, this
means that an OLA and SLA have been breached and the business is being
impacted. Exceptions could represent a total failure, impaired functionality or degraded
performance. Please note, though, that an exception does not always represent an incident. For example,
an exception could be generated when an unauthorized device is discovered on
the network. This can be managed by using either an Incident Record or a Request for Change (or even both), depending on the organization’s Incident and Change Management policies. Examples of exceptions include:
• A server is down
• Response time
of a standard transaction across the network has slowed to
more than 15 seconds
• More than 150 users have logged on to the General
Ledger application concurrently
• A segment of the network is not responding to
routine requests.
Event Correlation
If an event is significant, a decision has to be made about
exactly what the significance is and what actions need to be taken to deal with
it. It is here that the meaning of the event is determined.
Correlation is normally done by a ‘Correlation
Engine’, usually part of a management tool that compares the event with a set
of criteria and rules in a prescribed order. These criteria are often called
Business Rules, although they are generally fairly technical.
A Correlation Engine is programmed according to the
performance standards created during Service
Design and any additional guidance specific
to the operating environment.
Examples of what Correlation Engines will take into account include:
• Number of similar events (e.g. this is the third
time that the same user has logged in with the incorrect password, a business
application reports that there has been an unusual pattern of usage of a mobile
telephone that could indicate that the device has been lost or stolen)
• Number of CIs generating similar events
• Whether a specific action is associated with the
code or data in the event
• Whether the event represents an exception
• A comparison of utilization information in the event
with a maximum or minimum standard (e.g. has the device exceeded a threshold?)
• Whether additional data is required to investigate
the event further, and possibly even a collection of that data by polling
another system or database
• Categorization of the event
• Assigning a priority level to the event
An unplanned interruption to an IT service or
reduction in the quality of an IT service. Failure of a configuration
item that has not yet impacted service is also an
incident, for example failure of one disk from a mirror set.
Incident Management is the process for dealing with all incidents; this
can include failures, questions or queries reported by the users (usually via
a telephone call to the Service Desk), by technical staff, or automatically detected and
reported by event monitoring tools.
Purpose/goal/objective
The primary goal of the Incident Management process is
to restore normal service operation as quickly as possible and minimize the adverse impact on business operations, thus ensuring that the best possible levels of service quality and availability are
maintained. ‘Normal service operation’ is defined here as service operation
within SLA limits.
Scope
Incident Management includes any event which disrupts,
or which could disrupt, a service. This includes events which are communicated
directly by users, either through the Service Desk or through an interface from
Event Management to Incident Management tools.
Incidents can also be reported and/or logged by
technical staff (if, for example, they notice something untoward with a
hardware or network component they may report or log an incident and refer it to the Service Desk).
Although both incidents and service requests are reported
to the Service Desk, this does not mean that they are the same. Service
requests do not represent a disruption to agreed service, but are a way of
meeting the customer’s needs and may be addressing an agreed target in an SLA. Service
requests are dealt with by the Request Fulfilment process.
Incident Models
Many incidents are not new – they involve dealing with
something that has happened before and may well happen again. For this reason,
many organizations will find it helpful to pre-define ‘standard’ Incident Models – and apply
them to appropriate incidents when they occur.
An Incident Model is a way of pre-defining the steps
that should be taken to handle a process (in this case a process for dealing with a particular
type of incident) in an agreed way. Support tools can then be used to manage
the defined path and within pre-defined timescales.
Incidents which would require specialized handling can
be treated in this way (for example, security-related incidents can be routed to Information Security Management and capacity- or performance-related incidents that would be routed to Capacity Management.
The Incident Model should include:
• The steps that should be taken to handle the
incident
• The chronological order these steps should be taken
in, with any dependences or co-processing defined
• Responsibilities; who should do what
• Timescales and thresholds for completion of the actions
• Escalation
procedures; who should be contacted and when
• Any necessary evidence-preservation activities
(particularly relevant for security- and capacity-related incidents).
The models should be input to the incident-handling support tools in use and the
tools should then automate the handling, management and escalation of the process.
Major Incidents
A separate procedure, with shorter timescales and greater urgency, must be used
for ‘major’ incidents. A definition of what constitutes a major incident must be agreed and ideally mapped on to the overall incident
prioritization system – such that they will be dealt with through the major incident process.
Where necessary, the major incident procedure should
include the dynamic establishment of a separate major incident team under the
direct leadership of the Incident Manager, formulated to concentrate on this
incident alone to ensure that adequate resources and focus are provided to finding
a swift resolution. If the Service Desk Manager is also fulfilling the role of Incident
Manager (say in a small organization), then a separate person may need to be designated to
lead the major incident investigation team – so as to avoid conflict of time or
priorities – but should ultimately report back to the Incident Manager.
If the cause of the incident needs to be investigated at the same time,
then the Problem Manager would be involved as well but the Incident Manager
must ensure that service restoration and underlying cause are kept separate.
Process activities, methods and techniques

Work cannot begin on dealing with an incident until it
is known that an incident has occurred. It is usually unacceptable, from a business perspective, to wait until a user is impacted and contacts the Service Desk. As far
as possible, all key components should be monitored so that failures or potential failures are detected
early so that the Incident Management process can be started quickly.
Ideally, incidents should be resolved before they have an impact on
users!
Incident logging
All incidents must be fully logged and date/time stamped,
regardless of whether they are raised through a Service Desk telephone call or whether automatically detected
via an event alert.
It is important that if this is done, a separate Incident Record is logged for each additional incident handled and so that if the
incident has to be referred to other support
group(s), they will have all relevant
information to hand to assist them.
The information needed for each incident is likely to include:
• Unique reference number
• Incident categorization (often broken down into
between two and four levels of sub-categories)
• Incident urgency
• Incident impact
• Incident prioritization
• Date/time recorded
• Name/ID of the person and/or group recording the
incident
• Method of notification (telephone, automatic,
e-mail, in person, etc.)
• Name/department/phone/location of user
• Incident status
(active, waiting, closed, etc.)
• Related problem/Known Error
• Resolution date and time
• Closure
category
• Closure date and time.
Incident categorization
Part of the initial logging must be to allocate
suitable incident categorization coding so that the exact type of the call is recorded.
This will be important later when looking at incident types/frequencies to
establish trends for use in Problem
Management, Supplier Management and other ITSM
activities.
Multi-level categorization is available in most tools – usually to three
or four levels of granularity. For example, an incident may be categorized as
shown in Figure which is below this sentence.

All organizations are unique and it is therefore
difficult to give generic guidance on the categories an organization should
use, particularly at the lower levels. However, there is a technique that can
be used to assist an organization to achieve a correct and complete set of
categories – if they are starting from scratch! The steps involve:
1. Hold a brainstorming
session among the relevant support groups,
involving the SD Supervisor and Incident and Problem Managers.
2. Use this session to decide the ‘best guess’
top-level categories – and include an ‘other’ category. Set up the relevant logging tools
to use these categories for a trial period.
3. Use the categories for a short trial period (long
enough for several hundred incidents to fall into each category, but not too
long that an analysis will take too long to perform).
4. Perform an analysis of the incidents logged during
the trial period. The number of incidents logged in each higher-level category
will confirm whether the categories are worth having – and a more detailed
analysis of the ‘other’ category should allow identification of any additional
higher level categories that will be needed.
5. A breakdown analysis of the incidents within each
higher-level category should be used to decide the lower-level categories that
will be required.
6. Review and repeat these activities after a further period –
of, say, one to three months – and again regularly to ensure that they remain
relevant. Be aware that any significant changes to categorization may cause
some difficulties for incident trending or management reporting – so they
should be stabilized unless changes are genuinely required.
Incident Prioritization
Another important aspect of logging every incident is to
agree and allocate an appropriate prioritization code – as this will determine
how the incident is handled both by support tools and support staff.
Prioritization can normally be determined by taking
into account both the urgency of the incident (how quickly the business needs a resolution) and
the level of impact it is causing. An indication of impact is often (but not always) the
number of users being affected. In some cases, and very importantly, the loss of service to a single
user can have a major business impact – it all depends upon who is trying to do
what – so numbers alone is not enough to evaluate overall priority!
Other factors that can also contribute to impact levels are:
• Risk to life or limb
• The number of services affected – may be multiple
services
• The level of financial losses
• Effect on business reputation
• Regulatory or legislative breaches.
An effective way of calculating these elements and deriving an overall
priority level for each incident is given in Table

In all cases, clear guidance – with practical examples
– should be provided for all support staff to enable them to determine the
correct urgency and impact levels, so the correct priority is allocated. Such
guidance should be produced during service
level negotiations.
However, it must be noted that there will be occasions
when, because of particular business expediency or whatever, normal priority
levels have to be overridden. When a user is adamant that an incident’s
priority level should exceed normal guidelines, the Service Desk should comply with such a request – and if it
subsequently turns out to be incorrect this can be resolved as an off-line
management level issue, rather than a dispute occurring when the user is on the
telephone.
Some organizations may also recognize VIPs
(high-ranking executives, officers, diplomats, politicians, etc.) whose
incidents would be handled on a higher priority than normal – but in such cases this
is best catered for and documented within the guidance provided to the Service Desk staff on
how to apply the priority levels, so they are all aware of the agreed rules for
VIPs, and who falls into this category.
It should be noted that an incident’s priority may be dynamic – if
circumstances change, or if an incident is not resolved within SLA target
times, then the priority must be altered to reflect the new situation.
Initial Diagnosis
If the incident has been routed via the Service Desk,
the Service Desk Analyst must carry out initial diagnosis, typically while the user is still on the
telephone - if the call is raised in this way – to try to discover the full symptoms of the
incident and to determine exactly what has gone wrong and how to correct it. It
is at this stage that diagnostic
scripts and known error information can be most valuable in
allowing earlier and accurate diagnosis.
If possible, the Service Desk Analyst will resolve the incident while
the user is still on the telephone – and close the incident if the resolution is
successful. If the Service Desk Analyst cannot resolve the incident while the
user is still on the telephone, but there is a prospect that the Service Desk
may be able to do so within the agreed time limit without assistance from other
support groups.
Analyst should inform the user of their intentions,
give the user the incident reference number and attempt to find a resolution.
Incident Escalation
• Functional
escalation. As soon as it becomes clear that
the Service Desk is unable to resolve the incident itself (or when target times
for first-point resolution have been exceeded – whichever comes first!) the
incident must be immediately escalated for further support. If the organization has a
second-level support group and the Service Desk believes that the incident can
be resolved by that group, it should refer the incident to them. If it is
obvious that the incident will need deeper technical knowledge – or when the
second-level group has not been able to resolve the incident within agreed
target times (whichever comes first), the incident must be immediately
escalated to the appropriate third-level support group.
• Hierarchic
escalation. If incidents are of a serious
nature (for example
Priority 1 incidents) the appropriate IT managers must be notified, for
informational purposes at least. Hierarchic escalation is also used if the
‘Investigation and Diagnosis’ and ‘Resolution and Recovery’ steps are taking too long or proving too difficult.
Hierarchic escalation should continue up the management chain so that senior
managers are aware and can be prepared and take any necessary action, such as
allocating additional resources or involving suppliers/maintainers. Hierarchic escalation
is also used when there is contention about to whom the incident is
allocated.
The exact levels and timescales for both functional
and hierarchic escalation need to be agreed, taking into account SLA targets,
and embedded within support tools which can then be used to police and control the process
flow within agreed timescales.
The Service Desk should keep the user informed of any relevant
escalation that takes place and ensure the Incident Record is updated
accordingly to keep a full history of actions.
Investigation and Diagnosis
In the case of incidents where the user is just seeking
information, the Service Desk should be able to provide this fairly quickly and
resolve the service request – but if a fault is being reported, this is an
incident and likely to require some degree of investigation and diagnosis.
Each of the support groups involved with the incident
handling will investigate and diagnose what has gone wrong – and all such
activities (including details of any actions taken
to try to resolve or re-create the incident) should be fully documented
in the incident record so that a complete historical record of all activities is maintained at
all times.
This investigation is likely to include such actions as:
• Establishing exactly what has gone wrong or being
sought by the user
• Understanding the chronological order of events
• Confirming the full impact of the incident, including the
number and range of users affected
• Identifying any events that could have triggered the
incident (e.g. a recent change, some user action?)
• Knowledge searches looking for previous occurrences
by searching previous Incident/Problem
Records and/or Known Error Databases or
manufacturers’/suppliers’ Error Logs or Knowledge Databases.
Resolution and Recovery
When a potential resolution has been identified, this should be
applied and tested. The specific actions to be undertaken and the people who
will be involved in taking the recovery actions may vary, depending upon the nature of the fault – but could
involve:
• The Service Desk implementing the resolution either centrally (say,
rebooting a server) or remotely using software to take control of the user’s desktop to
diagnose and implement a resolution.
Incident Closure
The Service Desk should check that the incident is fully
resolved and that the users are satisfied and willing to agree the incident can
be closed. The Service Desk should also check the following:
• Closure categorization. Check and confirm
that the initial incident categorization was correct or, where the
categorization subsequently turned out to be incorrect, update the record so that a
correct closure categorization is recorded for the incident – seeking advise or
guidance from the resolving group(s) as necessary.
• User satisfaction survey. Carry out a user
satisfaction call-back or e-mail survey for the agreed percentage of incidents.
• Incident documentation. Chase any outstanding
details and ensure that the Incident Record is fully documented so that a full
historic record at a sufficient level of detail is complete.
• Ongoing or recurring problem? Determine (in conjunction with resolver
groups) whether it is likely that the incident could recur and decide
whether any preventive action is necessary to avoid this. In conjunction
with Problem Management, raise a Problem Record in all such cases so
that preventive action is initiated.
Purpose/goal/objective
Problem Management is the process responsible for managing the lifecycle of all
problems. The primary objectives of Problem Management are to prevent
problems and resulting incidents from happening, to eliminate recurring
incidents
and to minimize the impact of incidents that cannot be prevented.
Scope
Problem Management includes the activities required to diagnose the root cause of
incidents and to determine the resolution to those problems. It is also responsible for ensuring that the
resolution is implemented through the appropriate control procedures, especially Change Management and Release
Management.
Problem Management will also maintain information about problems and the appropriate workarounds and
resolutions, so that the organization is able to reduce the number and impact of incidents
over time. In this respect, Problem Management has a strong interface with Knowledge Management, and tools such as the Known Error
Database will be used for both.
Although Incident and Problem Management are separate processes, they
are closely related and will typically use the same tools, and may use similar
categorization, impact and priority coding systems. This will ensure effective communication when
dealing with related incidents and problems.
Value to business
Problem Management works together with Incident Management and Change Management to ensure that IT service availability and quality are increased. When incidents are resolved, information about the
resolution is recorded. Over time, this information is used to speed up the
resolution time and identify permanent solutions, reducing the number and
resolution time of incidents. This results in less downtime and less disruption to business
critical systems. Additional value is derived from the following:
• Higher availability of IT services
• Higher productivity of business and IT staff
• Reduced expenditure on workarounds or fixes that do not
work
• Reduction in cost of effort in
fire-fighting or resolving repeat incidents.
Problem Models
Many problems will be unique and will require handling
in an individual way – but it is conceivable that some incidents may recur
because of dormant or underlying problems (for example, where the cost of a
permanent resolution will be high and a decision has been taken not to go ahead
with an expensive solution – but to ‘live with’ the problem).
Process activities, methods
and techniques
Problem Management consists of two major processes:
Service Operation – and is therefore covered in this publication
• Proactive
Problem Management which is initiated in Service Operation, but generally
driven as part of Continual Service Improvement. The reactive Problem Management process is shown in
Figure which is below under this paragraph. This is a simplified chart to show
the normal process flow, but in reality some of the states may be iterative or
variations may have to be made in order to handle particular situations.

Problem detection
It is likely that multiple ways of detecting problems will exist in
all organizations.
These will include:
• Suspicion or detection of a cause of one or more incidents
by the Service Desk, resulting in a Problem
Record being raised – the desk may have
resolved the incident but has not determined a definitive cause and suspects that it is likely
to recur, so will raise a Problem Record to allow the underlying cause to be
resolved. Alternatively, it may be immediately obvious from the outset that an
incident, or incidents, has been caused by a major problem, so a Problem Record
will be raised without delay.
• Analysis of an incident by a technical support group which reveals that an underlying problem exists, or is likely to exist.
• Automated detection of an infrastructure or application fault, using event/alert tools automatically to raise an incident which may reveal the need for a
Problem Record.
• A notification from a supplier or contractor that a problem exists
that has to be resolved.
• Analysis of incidents as part of proactive Problem Management – resulting
in the need to raise a Problem Record so that the underlying fault can
be investigated further.
Problem Logging
Regardless of the detection method, all the relevant details of
the problem must be recorded so that a full historic record exists. This must be date and time
stamped to allow suitable control and escalation.
A cross-reference must be made to the incident(s) which initiated the
Problem Record – and all relevant details must be copied from the Incident Record(s) to the Problem Record. It is difficult to be exact, as cases may
vary, but typically this will include details such as:
• User details
• Service details
• Equipment details
• Date/time initially logged
• Priority and categorization details
• Incident description
• Details of all diagnostic or attempted recovery actions
taken.
Problem Categorization
Problems must be categorized in the same way as incidents
(and it is advisable to use the same coding system) so that the true nature of the problem can be easily
traced in the future and meaningful management
information can be obtained.
Problem Prioritization
Problems must be prioritized in the same way and for
the same reasons as incidents – but the frequency and impact of related incidents must also be
taken into account. The coding system described earlier in Table 4.1 (which combines impact
with urgency to give an overall priority level) can be used to prioritize problems in
the same way that it might be used for incidents, though the definitions and
guidance to support staff on what constitutes a problem, and the related service targets at each
level, must obviously be devised separately.
Problem prioritization should also take into account the severity of the
problems.
Severity in this context refers to how serious the problem is from an
infrastructure perspective, for example:
• Can the system be recovered, or does it need to be
replaced?
• How much will it cost?
• How many people, with what skills, will be needed to
fix the problem?
• How extensive is the problem (e.g. how many CIs are
affected)?
Problem Investigation and Diagnosis
An investigation should be conducted to try to
diagnose the root cause of the problem – the speed and nature of this
investigation will vary depending upon the impact, severity and urgency of the
problem – but the appropriate level of resources and expertise should be applied to
finding a resolution commensurate with the priority code allocated and the
service target in place for that priority level.
It is often valuable to try to recreate the failure,
so as to understand what has gone wrong, and then to try various ways of
finding the most appropriate and cost-effective resolution to the problem. To do this effectively without
causing further disruption to the users, a test system will be necessary that mirrors the production environment.
There are many problem analysis, diagnosis and
solving techniques available and much research has been done in this area. Some
of the most useful and frequently used techniques include:
• Chronological
analysis: When dealing with a difficult problem, there are often conflicting
reports about exactly what has happened and when. It is therefore very helpful
briefly to document all events in chronological order to provide a timeline of
events. This often makes it possible to see which events may have been triggered
by others – or to discount any claims that are not supported by the sequence of
events.
• Pain Value
Analysis: This is where a broader view is taken of the impact of an incident or problem, or incident/problem
type. Instead of just analyzing the number of incidents/problems of a
particular type in a particular period, a more in-depth analysis is done to
determine exactly what level of pain has been caused to the organization/business
by these incidents/problems.
Typically this might include taking into account:
• The number of people affected
• The duration of the downtime caused
• The cost to the business (if this can be readily calculated or
estimated).
By taking all of these factors into account, a much more detailed
picture of those incidents/problems or incident/problem types that are causing
most pain can be determined – to allow a better focus on those things that
really matter and deserve highest priority
in resolving.
• Pareto Analysis: This is a technique for
separating important potential causes from more trivial issues. The following
steps should be taken:
1. Form a table listing the causes and their frequency
as a percentage.
2. Arrange the rows in the decreasing order of
importance of the causes, i.e. the most important cause first.
3. Add a cumulative percentage column to the table. By
this step, the chart should look something like Table which is under this
paragraph, which illustrates 10 causes of network failure in an organization.

4. Create a bar chart with the causes, in order of their percentage of
total.
5. Superimpose a line chart of the cumulative percentages. The completed
graph is illustrated in Figure which is under this
paragraph.
6. Draw line at 80% on the y-axis parallel to the x-axis. Then drop the
line at the point of intersection with the curve on the x-axis. This point on
the x-axis separates the important causes and trivial causes. This line is
represented as a dotted line in Figure which is under
this paragraph.

From this chart it is clear to see that there are
three primary causes for network failure in the organization. These should therefore be targeted first.
Workarounds
In some cases it may be possible to find a workaround to the
incidents caused by the problem – a temporary way of overcoming the difficulties. For
example, a manual amendment may be made to an input file to allow a program to
complete its run successfully and allow a billing process to complete satisfactorily, but it
is important that work on a permanent resolution
continues where this is justified – in
this example the reason for the file becoming corrupted in the first place must
be found and corrected to prevent this happening again.
Raising a Known Error Record
As soon as the diagnosis is complete, and particularly where
a workaround has been found (even though it may not yet be a permanent
resolution), a Known Error Record must be raised and placed in the Known Error Database – so that if further incidents or problems arise, they can be identified
and the service restored more quickly.
Problem Resolution
Ideally, as soon as a solution has been found, it
should be applied to resolve the problem – but in reality safeguards may be
needed to ensure that this does not cause further difficulties. If any change in
functionality is required this will require an RFC to be raised and approved
before the resolution can be applied. If the problem is very serious and an
urgent fix is needed for business reasons, then an Emergency RFC should be
handled by the Emergency Change Advisory Board (ECAB). Otherwise, the RFC should follow the
established Change Management process for that type of change – and the resolution
should be applied only when the change has been approved and scheduled for release.
Problem Closure
When any change
has been completed (and successfully reviewed), and the resolution has been
applied, the Problem Record should be formally closed – as should any related Incident Records that are still open. A check should be performed at this time to
ensure that the record contains a full historical description of all events – and if not, the record should be
updated.
The status of any related Known Error
Record should be updated to shown that the
resolution has been applied.
Major Problem Review
After every major problem (as determined by the organization’s priority system), while memories are still fresh a review should be conducted to learn
any lessons for the future. Specifically, the review should examine:
• Those things that were done correctly
• Those things that were done wrong
• What could be done better in the future?
• How to prevent recurrence
• Whether there has been any third-party
responsibility and whether follow up actions are needed.
A Service Desk, is a primary IT service within the discipline of IT service management (ITSM) as
defined by the Information
Technology Infrastructure Library (ITIL). It is intended to provide a Single Point of
Contact (SPOC) to meet the communication needs of
both users and IT employees. But also to satisfy both Customer and IT Provider
objectives. "User" refers to the actual user of the service, while
"Customer" refers to the entity that is paying for service.
According to ITIL, the definition of a Service Desk is a
the single point of contact between users and IT Service Management. Tasks
include handling incidents and requests, and providing an interface for other ITIL processes. The primary functions of
the Service Desk are incident control, life cycle management of all service
requests, and communicating with the customer.

Interactions
of Service Desk
Service
Desk, is a center that provides a Single Point of Contact between a company’s customers,
employees and business partners. The Service Desk is designed to optimize
services on behalf of the business and oversee IT functions. Thus, a Service
Desk does more than making sure IT services are being delivered at that moment,
it manages the various lifecycles of software packages used to provide critical
information flow by utilizing ITIL best practices.
These best practices enable an IT service
provider to ensure end user data is being delivered consistently under many
different scenarios. Since the Service Desk is a Single Point of Contact (SPOC)
it understands that there are many reasons services can be interrupted. A
Service Desk has the means within its hierarchy to monitor and manage each
layer of service from beginning to end. These layers are classified by:
Network Operations: The ability to monitor all network devices and connections remotely. A Service Desk manages and monitors incident
reports, traffic, performs network reviews, implements backups and manages
change on the network. Thus, a Service Desk ensures the infrastructure of the
network is optimized to meet the business needs of the enterprise.
Systems Operations: The ability to perform core systems management tasks. Core systems
management include performance monitoring, installation of patches, change
management, account management and support for specific platforms, Linux, Unix,
etc.
Database Operations: The ability to
maintain and optimize database tasks. Performance monitoring, fault monitoring,
log reviews, access management, and change control for database software such
at Oracle, DB2, etc.
Security Management: The ability to
protect the enterprise from external/internal threats. A Service Desk will
perform vulnerability scans, monitor IPS logs and map this data to the
information security related regulatory mandates.
Service Desk Types
Many
organizations have implemented a central point of contact for handling
customer, user and other issues. The service desk types are based on the skill
level and resolution rates for service calls. The different service desk types
include:
Call Center: The main purpose is to
handle large volumes of telephone based transactions like telesales or order
processing.Call center is a centralised
office used for receiving or transmitting a large volume of requests by telephone. An inbound call centre is operated by a company to ADMINister incoming
product support or information inquiries from consumers. Outbound call centers
are operated for telemarketing,
solicitation of charitable or political donations, debt collection and market research.
Contact Center: A contact center is a central point in an enterprise from
which all customer contacts are managed. The contact center typically includes
one or more online call centers but may include other types of customer contact as well,
including e-mail newsletters, postal mail catalogs, Web site inquiries and
chats, and the collection of information from customers during in-store
purchasing. A contact center is generally part of an enterprise's overall customer relationship management.(CRM)
Help Desk: The main
purpose is to manage and resolve incidents quickly and effectively, and to
make sure that all requests are followed up . Help desk is a resource intended to provide the
customer or end user with information and support
related to a company's or institution's products and services.
The purpose of a help desk is usually to troubleshoot problems or provide guidance about
products such as computers, electronic equipment, food, apparel, or
software.
Corporations usually provide help desk support to their
customers through various channels such as toll-free numbers, websites, instant
messaging, or email. There are also in-house help desks designed to provide
assistance to employees.
Service Desk
Roles:
1.Service Desk Manager
In larger organizations where the Service
Desk is of a significant size, a Service Desk Manager role may be justified
with the Service Desk Supervisor(s) reporting to him or her. In such cases this
role may take responsibility for some of the activities listed above and may
additionally perform the following activities:
• Manage the
overall desk activities, including the supervisors
• Report to
senior managers on any issue that could significantly impact the
business
the Service Desk. This could
also be expanded to any other activity taken
2. Service
Desk Supervisor
as the Supervisor – but in
larger desks it is likely that a dedicated Service Desk
more post-holders who fulfil the
role, usually on an overlapping basis. The
Supervisor’s role is likely to
include:
• Ensuring that
staffing and skill levels are maintained throughout
operational hours by managing shift staffing schedules, etc.
• Production of
statistics and management reports
• Representing
the Service Desk at meetings
• Arranging staff
training and awareness sessions
• Performing
briefings to Service Desk staff on changes or deployments
that
may affect volumes at the
Service Desk
or where additional experience is required.
3.Service
Desk Analysts
The primary
Service Desk Analyst role is that of providing first-level support
objectives
described earlier.
2-)Overview of Technical Management
ITIL Technical
Management provides technical expertise and support for the management
of the IT infrastructure. Technical
Managements plays an important role in the technical aspects of designing, testing,
operating and improving IT services, as well as in developing the skills
required to operate the IT infrastructure required. Technical Management is a
part of Service Operation.
Technical Management plays a dual role:
• It is the
technical knowledge and expertise related to managing the IT Infrastructure. In this role,
Technical Management ensures that
the knowledge required to design, test, manage and
improve IT services is
identified, developed and refined.
{kind=link}
• It provides the
actual resources to support the ITSM Lifecycle. In this role
Technical Management ensures that resources are effectively trained and
deployed to design, build, transition, operate and improve the technology required to deliver and support IT services.
{kind=link}
Technical Management objectives
The objectives
of Technical Management are to help plan, implement and maintain a stable
technical infrastructure to support the organization’s business processes through:
• Well designed and highly resilient, cost-effective technical
topology
• The use of adequate technical skills to maintain the technical
infrastructure
in optimum condition
• Swift use of technical skills to speedily diagnose and resolve
any technical
failures
that do occur.
Technical
Management Organization
Technical Management is not normally provided by a single department or group.
One or more Technical Support teams or
departments will be needed to provide technical management and support for the IT Infrastructure. In all but the smallest
organizations, where a single combined team or department may suffice, separate
teams or departments will be needed for each type of infrastructure being used.
{kind=link}
The primary criterion of
Technical Management organizational structure is that of
specialization or division of labour. The
principle is that people are grouped according to their technical skill sets,
and that these skill sets are determined by the technology that needs to be
managed.
Below the list provides
some examples of typical Technical Management teams or departments:
• Mainframe team
or department : if one or more mainframe types are still being used by
the organization,
• Server team or
department : often split again by technology types (e.g.Unix server, Wintel
server),
• Storage team or
department : responsible for the management of all data
storage devices and media,
• Network Support
team or department, looking after the organization’s internal WANs/LANs and
managing any external network suppliers,
• Desktop team or
department, responsible for all installed desktop equipment,
• Database team
or department, responsible for the creation, maintenance
and support of the
organization’s databases,
and maintenance of all
middleware in use in the organization,
access and rights to service
elements in the infrastructure.
Technical Management roles
The following roles are needed in the Technical
Management areas:
Technical Managers/Team-leaders
Technical
Manager or Team-leader (depending upon the size or importance of the team and
the organization’s structure and culture) may be needed for each of
the technical teams or departments. The role will:
the technical team or
department,
covered by the team or
department,
• Ensure
necessary technical training, awareness and experience levels are
maintained within the team or
department,
• Report to
senior management on all technical issues relevant to their area
of responsibility,
Technical
Analysts/Architects
• Working with users, sponsors, Application Management and all other stakeholders to determine their evolving needs,
• Working with
Application Management and other areas in Technical Management to determine the
highest level of system requirements required to
meet the requirements within budget and technology constraints,
• Defining and
maintaining knowledge about how systems are related and ensuring that
dependencies are understood and managed accordingly,
means to meet the stated
requirements,
IT Operations Management
What is
Operations Mageanment?
Operations Management deals with the
design and management of products, processes, services and supply chains. It
considers the acquisition, development, and utilization of resources that firms
need to deliver the goods and services their clients want.
The purvey of OM ranges from strategic to
tactical and operational levels. Representative strategic issues include
determining the size and location of manufacturing plants, deciding the
structure of service or telecommunications networks, and designing technology
supply chains.
Tactical issues include plant layout and structure,
project management methods, and equipment selection and replacement.
Operational issues include production scheduling and control, inventory
management, quality control and inspection, traffic and materials handling, and
equipment maintenance policies.
Operations
management is an area of management concerned with overseeing, designing, and
controlling the process of production and redesigning business operations (http://en.wikipedia.org/wiki/Business_operations) in the production of goods or services. It involves the responsibility of ensuring that business operations
are efficient in
terms of using as few resources as needed, and effective in
terms of meeting customer requirements. It is concerned with managing the
process that converts inputs (in the forms of raw materials ,
labor and energy) into outputs (in the form of
goods and/or services).[2] The
relationship of operations management to senior management in commercial contexts can be compared to the
relationship of line officers to highest-level senior officers in military science . The highest-level officers shape the strategy and revise it over time, while the line
officers make tactical decisions in support of carrying out the strategy. In business as in
military affairs, the boundaries between levels are not always distinct;
tactical information dynamically informs strategy, and individual people often
move between roles over time.
Take of
Service Operation
The purpose of this painting includes
service operations and goals.

Scope of Service Operation
Implementation of
all ongoing activities :
·
The services themselves, i.e., all activities that are part of a service, independent of who is
performing it (IT service provider, external supplier, user or customer).
·
Service management processes, i.e., all
operational activities, even if they originate from another phase of the
service life cycle.
·
Technology, i.e.,
integrated management of the technology provided for the services takes
place during Service Operation.
·
Persons, i.e. scheduling and management of the
necessary know how for performing the Service Operations.[3]
Value to the
business:
·
Reduction of unplanned staffing expenses
and costs.
·
Reduction of the duration and frequency
of service failures.
·
Providing quick and effective access to
Standard services.
·
Providing a basis for an automated
operation.
Roles of good
communication in Service Operation:
·
Good communication is required.
·
Avoids problematic situations.
·
Principle: must pursue a specific purpose
or triggeran action.
·
·
Communication includes:
ü
Routine communication at the facility.
ü
Performance reporting.
ü
Communication in projects.
ü
Training regarding new processes or
Service Designs.
IT Operations
To focus on delivering the service as agreed with the
customer, the service provider will first have to manage the technical
infrastructure that is used to deliver the services. Even when no new customers
are added and no new services have to be introduced, no incidents occur in existing services, and
no changes have to be made in existing services services – the IT organization will be busy with a range of service operation. These
activities focus on actually delivering the agreed service.
IT Operations Management
In business,
the term ‘Operations Management’ is used to
mean the department, group or team of people responsible for performing the
organization’s day-to-day operational activities – such as
running the production line in a manufacturing environment or managing the distribution centres and fleet movements
within a logistics organization.
Operations Management generally
has the following characteristics:
• There is work
to ensure that a device, system or process is actually
running or working (as opposed to strategy or planning)
• This is where plans are turned into actions
• The focus is on
daily or shorter-term activities, although it should be noted that these
activities will generally be performed and repeated over a relatively long
period (as opposed to one-off project type
activities)
• These
activities are executed by specialized technical staff, who often have to
undergo technical training to learn how to perform each activity
• There is a
focus on building repeatable, consistent actions that – if repeated frequently
enough at the right level of quality – will ensure
the success of the operation
• This is where
the actual value of the organization is
delivered and measured
• There is a dependency on investment in
equipment or human resources or both
• The value generated,
must exceed the cost of the investment and
all other organizational overheads (such as
management and marketing costs) if the business is to succeed.
In a similar
way, IT
Operations Management can be defined as the function
responsible for the ongoing
management and maintenance of an organization’s
IT Operations can be defined as the set of activities involved in the
day-to-day running of the IT Infrastructure for the purpose of
delivering IT services at agreed levels to meet stated business objectives.
IT operations management has two
functions: IT operations
control, which
ensures that routine operational tasks are carried out to deliver agreed IT
services, and facilities
management, for the management of physical IT environment, usually
data centers or computer rooms.

IT
operations control oversees all operational activities and IT infrastructure
events. This can be done with the help of an operations bridge or network operations center. IT operations control is responsible for tasks
including console management, job scheduling, backup and restore, print and
output management, and performance and maintenance activities. In many cases,
staff from technical and application management groups form part of the IT
operations management function.
IT
operations management is responsible for documentation like standard operating
procedures(SOPs),
operation logs, shift schedules and reports, and operation schedules.
IT operations is a separate function
within the IT organization, with clear tasks and rights. However, the technical
and application management frequently also take over parts of the day-to-day
operation and therefore perform an integrated operations function covering
multiple teams. There is no central method for the clear separation of tasks
between operation and engineering as this is dependent to a significant extent
upon the IT infrastructure’s degree of maturity and stability.

In the business the term “operations management” is used for
that part of the organization which controls and monitors the operational
day-to-day business.
This
is also the case within the IT: there is a whole range of activities which
relate to all aspects of IT service delivery. These can be ensuring that
systems are started up, data is backed up, reports printed or batch jobs
executed.
The role of IT operations management consists of performing
continuous activities as well as the control and maintenance of the IT
infrastructure so the services can be delivered and supported in accordance
with the agreed service level agreement.
This role
can be summarized as follows:
·
On
the one side, operations control, in other words the processing of
the console management, job scheduling, backup & restore procedures,
printout and output management as well as the maintenance work for the various Technologies
·
On
the other side, this also includes the facility management which
relates to the management of the physical IT environment. Typically this
includes the data center rooms, recovery sites or network
room as well as securing the air-conditioning and a reliable power supply.
IT Operations Management role
The role of Operations
Management is to execute the ongoing activities and procedures required to
manage and maintain the IT Infrastructure so as to deliver and support IT
Services at the agreed levels. These have already been described in section 5,
but are summarized here for completeness:
•
Operations
Control, which oversees the execution and monitoring of the operational
activities and events in the IT Infrastructure.
This can be done with the assistance of an Operations Bridge or Network
Operations Centre. In addition to executing routine tasks from all technical
areas,
Operations
Control also performs the following specific tasks:
• Console Management, which refers
to defining central observation and monitoring capability and then
using those consoles to exercise monitoring and control activities
• Backup and Restore on behalf of
all Technical and Application Management teams and departments and often on
behalf of
users
• Print and Output management for the
collation and distribution of all centralized printing or electronic output
• Performance of maintenance activities on behalf of
Technical or
Application Management teams or departments.
•
Facilities
Management, which refers to the management of the physical IT environment,
typically a Data Centre or computer rooms and recovery sites together with all
the power and cooling equipment. Facilities Management also includes the
coordination of large-scale consolidation projects, e.g. Data Centre
consolidation or server consolidation projects.
In some cases the
management of a data centre is outsourced, in which case Facilities Management
refers to the management of the outsourcing contract.
As with many IT Service
Management processes and functions, IT Operations Management plays a dual role.
• IT Operations Management is responsible for executing the
activities and performance standards defined
during Service Design and tested
during Service Transition. In this sense IT Operations’ role is primarily to
maintain the status quo. The stability of the IT Infrastructure and consistency of IT
services is a primary concern of IT Operations. Even operationalimprovements
are aimed at finding simpler and better ways of doing the same thing.
• At the same time, IT Operations is part of the process of adding value to the different lines of business and to
support the value network (see the ITIL Service Strategy publication).
The ability of the business to meet its objectives and to remain competitive depends on the
output and reliability of the day-to-day operation of IT. As such, IT
Operations Management
must be able to continually adapt to
business requirements and demand.The Business does not care that IT Operations
complied with a Standard procedure or that a server performed optimally. As
business demand and requirements change, IT Operations Management must be able
to keep pace with them, often challenging the status quo.
Scope and Role:
·
Department,
group or team with responsibility for day-to-day operational activities.
·
On-going
management and administration of the IT infrastructure to assure the aggreed
upon service level goals.
·
Maintaining
the current status of service provisioning.
·
Regular
inspection and improvement of the service at reduced costs.
·
Quick
deployment of operational capabilities for diagnosis and solution of
interruptions and problem in IT operations.
Application Management
Application Management is
responsible for managing applications throughout their
lifecycle. The
Application Management function is performed by any department, group or team
involved in managing and supporting operational applications.
Application Management also plays an important role in the design, testing and improvement of
applications that form part of IT services. As such, it may be involved in
development projects, but is not usually the same as the Applications
Development teams.
Application
Management role
Application Management is
to applications what Technical Management is to the IT Infrastructure. Application
Management plays a role in all applications, whether purchased or developed
in-house. One of the key decisions that they contribute to is the decision of
whether to buy an application or build it (this is discussed in detail in the
Service Design publication). Once that decision is made, Application Management
will play a dual role:
• It is the custodian of
technical knowledge and expertise related to managing applications. In this
role Application Management, working together with Technical Management,
ensures that the knowledge required to design, test, manage and improve IT
services is identified, developed and refined.
• It provides the actual
resources to support the ITSM Lifecycle.
In this role, Application Management ensures that resources are effectively
trained and deployed to design, build, transition, operate and improve the
technology required to deliver and support IT services.
By performing these two roles,
Application Management is able to ensure that
the organization has access to the right
type and level of human resources to
manage applications and thus to meet
business objectives. This starts in Service
Strategy and is expanded in Service Design,
tested in Service Transition and
series).
these resources.
In additional to these two
high-level roles, Application Management also performs
the following two specific roles:
• Providing guidance to IT Operations
about how best to carry out the ongoing operational management of applications.
This role is partly carried out during the Service Design process, but it is
also a part of everyday communication with IT Operations Management as they
seek to achieve stability and optimum performance.
• The integration of the
Application Management Lifecycle into the ITSM Lifecycle. This is discussed
below.
The objectives, activities and structures
that enable Application Management to
play these roles effectively are discussed below.
Application Management Lifecycle
The lifecycle followed to
develop and manage applications has been referred to
by many names, including the Software Lifecycle (SLC) and Software Development
Lifecycle (SDLC). These are generally used by Applications Development
teams and their Project Managers to define their involvement in designing, building,
testing, deploying and supporting applications. Examples of these approaches
are Structured Systems Analysis and Design Methodology (SSADM), Dynamic Systems
Development Method (DSDM), Rapid Application Development (RAD), etc.
ITIL is primarily
interested in
the overall management of applications as part of IT
For this reason, the term Application Management
Lifecycle has been used, as it
implies a more holistic view.
This should not
replace the
SDLC, which is still a valid approach used by developers, especially by
third-party software companies. However, it does mean that there should be
greater alignment between the development view of applications and the ‘live’
management of those applications.
This is more difficult in
large-scale purchased applications, such as e-mail, since
the developers do not typically interact
individually with their application’s users.
However, the basic lifecycle still holds
true in that the application needs
requirements, design, customization,
operation and deployment. Optimization is
achieved through better management,
improvements to customization and
upgrades.
The Application Management Lifecycle is illustrated as
follows:

ITSM processes
and Applications Development processes have to be aligned as
part of the overall strategy of delivering IT
services in support of the business.
Applications
Development and Operations are part of the same overall lifecycle
and both should be involved at
all stages, although their level of involvement will
vary
depending on the stage of the lifecycle.
Relationship between the Application Management and Service
Management
Lifecycles
The Application
Management Lifecycle should not be seen as an alternative to the Service
Management Lifecycle. Applications are part of services and have to be managed
as such. Nevertheless, applications are a unique blend of technology and
functionality and this requires a specialized focus at each stage of the
Service Management Lifecycle.
Each stage of
the Application Management Lifecycle has its own specific set of objectives, activities, deliverables and dedicated
teams. Each stage also has a clear responsibility to ensure that their outputs
match up to the specific objectives of the Service Management Lifecycle.
Different aspects of Application Management are covered in detail in each of
the ITIL publications, as follows:
• Service Strategy: Defines the overall architecture of
applications and infrastructure. This will include defining the criteria for
developing inhouse, outsourcing development, or purchasing and customizing
applications. Service Strategy will also assist in defining the Service Portfolio (including
applications) which
also includes information about the Return on Investment of applications and
the services they support. Thus high-level requirements are set during this
phase.
• Service Design: Helps to
establish requirements for functionality and manageability of applications and works with Development
teams to ensure that they meet these objectives. Service Design covers most of
the Requirements phase and is involved during the Build phase of the
Application Management Lifecycle.
• Service Transition: Application
Development and Management teams are involved in testing and validating what
has been built and deploying it operationally.
• Service Operation: This covers the
Operate phase of the Application Management Lifecycle. These processes and
structures are discussed in detail in this publication.
• Continual Service
Improvement: Covers the Optimize phase of the Application Management Lifecycle.
Continual Service Improvement measures the quality and relevance of
applications in operation and provides recommendations on how to improve
applications if there is a clear Return on Investment for doing so.
Application Management teams or departments will be needed for
all key
applications.
The exact nature of the role will vary depending upon the applications being supported,
but generic responsibilities are likely to include:
• Third-level support for incidents related to the application(s)
covered by that team or department
• Involvement in operation testing plans and deployment issues
• Application bug tracking and patch management (coding fixes for
in-house code, transports/patches for third-party code)
• Involvement in application operability and supportability issues
such as error code design, error messaging, event management hooks
• Application sizing and performance; volume metrics and load
testing etc.
• Involvement in developing Release Policies
• Identification of enhancements to existing software, both from a
functionality and manageability perspective.
Organizational roles
Traditionally,
Application Development and Management teams and departments
have been autonomous units. Each
one manages its own environment in
its own
way and each has a separate
interface to the business. This is illustrated in
Table
1.

Table 1
Organizational roles
Over
the last several years, these two worlds are being brought together by recent
moves to Object Oriented and SOA
approaches,
together with growing pressure from the Business to be more responsive and easy
to work with.
This means that Application
Development will have greater accountability for the successful operation of
applications they design, while Application Management
will have
greater involvement in the development of applications.

Figure
5 : Role of teams in the Application Management Lifecycle
Figure 5 shows a common
Application Management Lifecycle with involvement
from both groups. In this diagram it is
clear that Application Development will be
driving some phases with input from
Application Management. In other cases
Application Management will be driving the
phase with input and support from
Application Development. Both groups are
subordinated to the IT Service
Strategy of the organization and their
efforts are coordinated through Service
Transition mechanisms and processes.
Kaynakça
·
3. Training Document ITIL ® 2011
Foundation